
연관성규칙생성(Association Rule Discovery)은 데이터 분석과 데이터 마이닝에서 빠질 수 없는 매우 잘 알려진 알고리즘이다. 대표적인 무감독학습 방식의 분석 방법으로 소위 장바구니분석이라는 이름으로도 널리 알려져 있다. 맥주를 사면 기저귀를 산다는 식의 확률적인 규칙을 찾아내는 방법이다. 물론 맥주와 기저귀라는 우화는 상당 부분 포장된 이야기라는 사실도 알려져 있다.
그러나, 연관성규칙은 유용성이 상당히 크고, 신축적인 특성도 가지고 있어, 잘 이해하고 활용한다면 실무적으로도 다양한 용도 즉, 교차판매, 개인화, 상품 추천 등에 응용하기에 용이하다.
R에서는 여러 패키지를 통해서 이미 구현된 알고리즘을 제공하고 있기에 초심자들은 간단히 이미 제공되는 것들을 사용하면 된다. 하지만, 그 구현의 원리를 이해하고 간단한 스크립트를 통해 직접 Rule Set을 추출하는 과정을 수행할 수 있다면 더 좋은 공부가 될 수 있을 것이며, 실무에 적용하기 위해 다양한 응용을 할 수도 있을 것이다. 남들이 만들어 놓은 패키지나 라이브러리를 불러 사용하는 것과 본인이 데이터를 가공하여 직접 규칙을 추출할 수 있는 것은 차원이 다른 문제일 것이다.
예제에서는 아래의 공개된 수퍼마켓 쇼핑 데이터 셋 중 하나를 연습용으로 활용한다.
15만 구매내역 레코드로 구성되어 있으며, 6만건의 거래건이 들어 있다.
스크립트는 매우 간단하고 일반적인 기본형태를 가지고 있기에, 다른 데이터를 적용하는 것도 어렵지 않을 것이다. 공개된 수퍼마켓 쇼핑 데이터 셋은 상당히 많다. 예를들면 아래 주소에도 소개되고 있다. 무비렌즈의 영화추천 데이터셋을 사용해서도 같은 작업을 해볼 수 있을 것이며, 이 데이터는 R의 패키지 중 하나인 recommenderlab을 설치하면 data(MovieLense) 라는 구문으로 바로 불러 올 수 있다.
http://recsyswiki.com/wiki/Grocery_shopping_datasets
바로 예제로 넘어가면, 우선 CSV 포맷으로 저장된 데이터를 불러들이고, 확인한다.
데이터는 거래건의 번호와 상품번호라는 단 두개의 컬럼만으로 구성된 dataframe이 된다.
이 데이터셋을 거래건 번호를 기준으로 자기 자신과 병합시켜주면
하나의 거래번호에 대한 상품간의 조합을 만들 수 있다. [isa01]
기준이 되는 상품번호가 itemid.x, 그에 대한 조합인 상품번호가 itemid.y가 된다.
예를들어 설명하면 1번 거래건에 맥주라는 상품과 라면이라는 상품 두 가지가 모두 들어있다는 식의 조합을 나타내는 dataframe이 하나 생긴 것이다.
이 데이터를 이용해서 규칙에 대한 모든 계산이 가능하다.
#========[ association-rule discovery ]========
# load supermarket shopping data in dataframe format
setwd("C:/Users/yong000/Desktop/restore_Yong/recomm")
postr <- read.csv("pos_items.csv")
postr <- postr[,2:3]
# create a transaction matrix
isa01 <- merge(postr, postr, by="trid", all.x=T)
isa01 <- isa01[isa01$itemid.x!=isa01$itemid.y,]
head(isa01)
trid itemid.x itemid.y
2 28 10307 10311
3 28 10307 12487
4 28 10311 10307
6 28 10311 12487
7 28 12487 10307
8 28 12487 10311
위의 예에서 10307 번 상품과 10311 번 상품이 하나의 조합이다. 이제 규칙의 후보가 되는 각 조합의 발생빈도(=Support)를 계산한다. aggregate 함수에서 집계를 위한 함수로 갯수 즉 length()를 사용한다.
# compute support
isa02 <- aggregate(.~itemid.x+itemid.y, isa01, function(x) length(x))
head(isa02[order(-isa02$trid),])
names(isa02)[3] <- "cntrule"
다음으로 전체 데이터에서의 상품별 발생빈도를 구한다.
# compute item popularity
isa03 <- aggregate(.~itemid, postr, function(x) length(x))
names(isa03)[2] <- "cntitem"
연관성 규칙에서는 Confidence, Support, Lift라는 세가지 지표를 사용한다. 상세한 소개는 위키피디아 정도를 보면 충분한 정보가 제공되지만 간단하게 요약해본다.
Confidence는 규칙의 확률이다. 빵을 샀을때 맥주도 살 확률이라고 생각하면 된다.
Support는 모든 건들 중에서 빵과 맥주를 같이 사는 경우의 확률이다. 만건 중 빵과 맥주를 같이 산 경우가 포함된 건이 100건이면 0.01이 된다.
Lift는 빵을 산다는 조건이 붙은 경우와 붙지 않은 경우의 맥주를 살 확률간의 차이 비율이다. 빵이라는 조건이 없이 전체에서는 5%의 확률이지만 빵이라는 조건이 붙으면 10%가 된다고 하면 결과는 2가 된다. 확률이 두배 높아졌다는 것이다.
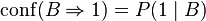

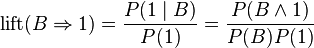
merge 함수를 사용하여 각 아이템의 구매빈도와 아이템간 조합의 건수를 하나로 결합한다.
조합(=Rule)의 빈도를 각 아이템의 빈도로 나누면 Confidence가 구해진다.
이어서 전체 거래건의 수로 조합의 빈도를 나누면 Support가 비율로 구해진다.
Lift는 Confidence를 규칙에서 결과쪽 부분에 해당하는 아이템의 발생빈도를 거랜건의 수로 나눈 값으로 나누어 주어 구한다. 위의 수식을 보면 좀 더 클리어할 수 있을 것이다.
# compute measures
isa04 <- merge(isa02, isa03, by.x="itemid.x", by.y="itemid", all.x=T)
isa04$rconf <- isa04$cntrule / isa04$cntitem
ntrid <- length(unique(postr$trid))
isa04$rsupp <- isa04$cntrule / ntrid
isa05 <- merge(isa04, isa03, by.x="itemid.y", by.y="itemid", all.x=T)
names(isa05) <- c("itemid","itemidy","cntrule", "cntitem", "rconf", "rsupp", "cntitemy")
isa05$rlift <- isa05$rconf / (isa05$cntitemy / ntrid)
nrow(isa05)
모두 127,946개의 규칙이 생겨났다. 이미 규칙을 찾는 것 자체는 끝이 난 것이다. 문제는 이 많은 규칙들이 다 쓸모가 있는 것은 아니라는 점이다. 규칙이란 여러번 반복해서 발생되었을때 믿음을 가질 수 있기 때문이다. 따라서 세가지 지표 즉 Confidence, Support, Lift를 일정 범위로 설정해서 전체 중 관심있는 부분의 규칙을 골라낸다.
# select rule set
isa06 <- isa05[isa05$rconf>=0.05 & isa05$rlift>1 & isa05$rsupp>=0.005, ]
nrow(isa06)
선별된 규칙의 구성을 Plot을 통해서 확인하고, 규칙에서 지표들을 기준으로 정렬하여
규칙의 내용을 살펴본다. 이제 완성된 것이다.
# explore relationship between measures
plot(jitter(isa06$rconf), jitter(isa06$rsupp), main="Association Rules - Confidence Vs. Support")
plot(jitter(isa06$rconf), jitter(isa06$rlift), main="Association Rules - Confidence Vs. Lift")
plot(jitter(isa06$rsupp), jitter(isa06$rlift), main="Association Rules - Support Vs. Lift")

head(isa06[order(-isa06$rlift),])
itemid itemidy cntrule cntitem rconf rsupp cntitemy rlift
98743 33453 33433 305 891 0.3423120 0.005117278 651 31.34022
97020 33433 33453 305 651 0.4685100 0.005117278 891 31.34022
51875 12831 12795 359 908 0.3953744 0.006023288 1180 19.97043
48630 12795 12831 359 1180 0.3042373 0.006023288 908 19.97043
48779 12795 12819 307 1113 0.2758311 0.005150834 908 18.10582
50899 12819 12795 307 908 0.3381057 0.005150834 1113 18.10582
# ----------- End of Scrip ----------------
이 처럼, 생각보다는 단순한 과정을 거쳐 말로만 듣던, 또는 패키지들을 사용해서나 도출할 수 있었던 연관성규칙을 직접 구할 수 있다. 이 과정을 이해했다면 다양한 응용은 직접 생각해낼 수 있을 것이다.
여기서는 R의 merge, aggregate 정도만 사용해서 기본 스크립트로 구현한 것이지만, 익숙한 사람은 SQL로도 유사하게 처리할 수 있을 것이다.
아무리 복잡한 알고리즘도 모두 이런 과정을 거쳐 누군가는 직접 프로그래밍을 통해 만든 것이다. 이제 좀 더 복잡한 무언가에 도전해 본다면?
#========[ association-rule discovery ]========
# load supermarket shopping data in dataframe format
setwd("C:/Users/yong000/Desktop/restore_Yong/recomm")
postr <- read.csv("pos_items.csv")
postr <- postr[,2:3]
# create a transaction matrix
isa01 <- merge(postr, postr, by="trid", all.x=T)
isa01 <- isa01[isa01$itemid.x!=isa01$itemid.y,]
head(isa01)
# compute support
isa02 <- aggregate(.~itemid.x+itemid.y, isa01, function(x) length(x))
head(isa02[order(-isa02$trid),])
names(isa02)[3] <- "cntrule"
# compute item popularity
isa03 <- aggregate(.~itemid, postr, function(x) length(x))
names(isa03)[2] <- "cntitem"
# compute measures
isa04 <- merge(isa02, isa03, by.x="itemid.x", by.y="itemid", all.x=T)
isa04$rconf <- isa04$cntrule / isa04$cntitem
ntrid <- length(unique(postr$trid))
isa04$rsupp <- isa04$cntrule / ntrid
isa05 <- merge(isa04, isa03, by.x="itemid.y", by.y="itemid", all.x=T)
names(isa05) <- c("itemid","itemidy","cntrule", "cntitem", "rconf", "rsupp", "cntitemy")
isa05$rlift <- isa05$rconf / (isa05$cntitemy / ntrid)
nrow(isa05)
# select rule set
isa06 <- isa05[isa05$rconf>=0.05 & isa05$rlift>1 & isa05$rsupp>=0.005, ]
nrow(isa06)
# explore relationship between measures
plot(jitter(isa06$rconf), jitter(isa06$rsupp))
plot(jitter(isa06$rconf), jitter(isa06$rlift))
plot(jitter(isa06$rsupp), jitter(isa06$rlift))
head(isa06[order(-isa06$rlift),])
# ----------- End of Scrip ----------------
'R 데이터 분석' 카테고리의 다른 글
| [SCWHO] 시각적 데이터 분석 EDA 예제 MLB Hitting 2016mid (0) | 2016.07.05 |
|---|---|
| [R분석] 플롯에서 X축변경 예제 reassign x axis value in R plot (0) | 2016.06.16 |
| [R 데이터 처리] 도로명 주소에서 동이름 추출 (0) | 2015.12.29 |
| ANN Example (0) | 2015.08.13 |
| R d3netwrok sample using randomForest proximity of mtcars (0) | 2015.08.05 |