
파이썬 시각화 분석:
쉽지만 모르는 사람들이 많은 유용한 팁 5 (matplotlib)
* * 파이썬 시각화 분석을 matplotlib을 사용해서 많이 하지만, 쉬운데도 잘 모르는 사람들이 많은 유용한 팁들 5가지 입니다. 파이썬을 사용해서 챠트를 작성해 시각적으로 데이터 분석을 하는 방법들은 많이들 공부하고 있고 또 사용하고 있기 때문에 유용한 것들은 이미 많이 알려져 있습니다.
그래도 그 중에서 쉽지만 사람들이 많이 알지 못하는 하지만 매우 유용한 숨겨진 팁들 몇가지를 ChatGPT에게 조사해보라 어려운 일을 시켜 봤습니다. 역시 ChatGPT를 적절히 활용하면 좀 더 쉽게 그리고 빠르게 데이터 분석 실력을 업그레이드할 수 있지 않을까 생각해봅니다.
(참고로, ChatGPT 3.5로 작업한 결과라 아래 내용을 복사해 넣고 유사한 예제를 만들어 달라거나, 주석을 달아 설명해달라고 해도 잘 해줍니다.)

[1] 색상 팔레트 활용: plt에서 제공하는 색상 팔레트를 사용하여 그래프를 더 예쁘게 만들 수 있습니다.
물론 데이터 분석 측면의 시각화에서 여러 색상을 사용하는 것은 주의해야할 사항입니다. 하지만 때로는 단순히 색상을 다양하게 해서 화려하게 하는 경우도 있을수 있으니 그런 용도에서 쓸모있는 팁입니다. 데이터 값의 갯수만큼 색상을 지정해서 사용하는 방법입니다.
import matplotlib.pyplot as plt
colors = plt.cm.viridis(np.linspace(0, 1, len(df01))) # 데이터 수에 따라 색상을 생성
x = df01[df01.columns[1]] # x 축 좌표 데이터
y = df01[df01.columns[2]] # y 축 좌표 데이터
plt.scatter(x, y, c=colors, alpha=0.5, s=100)
plt.show()
[2] 그래프 주석 추가: plt.annotate()를 사용하여 그래프에 주석을 추가할 수 있습니다.
이는 특정 데이터 포인트를 강조하는 데 유용합니다.
이 코드는 중요한 데이터 포인트를 강조하기 위해 plt.annotate() 함수를 사용한 간단한 산점도 그래프를 생성합니다. 앞에서 사용한 그래프를 그대로 사용해봅니다.
주석은 중요한 데이터 포인트에 화살표로 연결되고, xy 및 xytext 인수를 사용하여 주석의 위치를 지정합니다. 이 예제를 실행하면 주석이 있는(여러 업무 중에 어느 것이 중요한, 당신이 속한 업무인지 표시한) 그래프가 생성됩니다.
colors = plt.cm.viridis(np.linspace(0, 1, len(df01))) # 데이터 수에 따라 색상을 생성
x = df01[df01.columns[1]]
y = df01[df01.columns[2]]
plt.scatter(x, y, c=colors, alpha=0.5, s=100)
# 강조하고 싶은 데이터 포인트 선택 (좌표)
xy_point = list(df.head(5).tail(1).values[0])[1:]
# 선택한 데이터 포인트에서 x와 y 좌표 값 각각을 추출합니다.
x_point = xy_point[0]
y_point = xy_point[1]
# 주석 시작점을 계산합니다.
x_point_from = x_point + 1
y_point_from = y_point + 10
# 그래프 생성 및 주석 추가
plt.annotate('Your Job', xy=(x_point, y_point), xytext=(x_point_from, y_point_from),
arrowprops=dict(arrowstyle='->', connectionstyle='arc3,rad=0.5'))
plt.show()

[3] 로그 스케일 사용: plt.xscale('log') 또는 plt.yscale('log')를 사용하여 로그 스케일로 그래프를 그릴 수 있습니다.
특히 데이터가 지수적으로 증가하는 경우 유용합니다. 데이터 분포상 쏠리는 이런 경우에는 챠트를 작성해도 패턴을 시각적으로 인지하기 어려운 문제가 흔히 생깁니다. 이 때문에 데이터에 로그를 취하는 방식이 많이 사용됩니다. 축 자체의 스케일 변경하면 이 작업을 매우 쉽게 처리할 수 있습니다.
# 지수적으로 증가하는 데이터 값의 예시
x = [1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, 8192, 16384, 32768, 65536, 131072, 262144, 524288]
y = [1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, 8192, 16384, 32768, 65536, 131072, 262144, 524288]
# 기본 형태로 그래프를 그린 경우
plt.scatter(x, y, alpha=0.5)
plt.show()
# 로그 스케일로 축을 지정해서 그리는 경우
plt.xscale('log') # X축을 로그 스케일로 설정
plt.yscale('log') # Y축을 로그 스케일로 설정
plt.scatter(x, y, alpha=0.5)
plt.show()
# 위의 결과는 원래의 지수적으로 증가하는 분포의 값을 그대로 시각화한 것.
# 아래의 결과는 양쪽 축 모두에 로그스케일을 적용한 것. 로그스케일 적용 후 직선을 따라 일정한 간격으로 점이 배치된 패턴으로 변화되었음

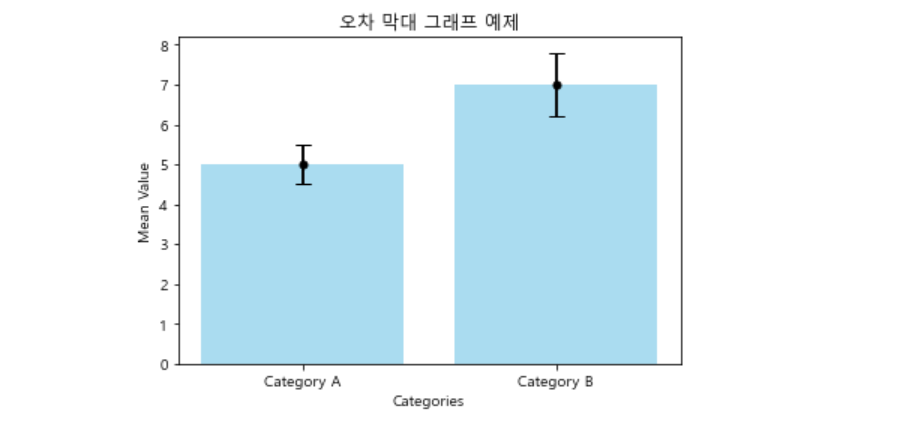
[4] 오차 막대 그래프: 오차 막대 그래프를 그려 데이터의 평균과 표준 편차 또는 신뢰 구간을 시각화할 수 있습니다.
원시 데이터를 plt.scatter() 등으로 개별적으로 살펴볼 수 도 있지만, 단순화하기 위해 평균 같은 대표값을 보여준다고 했을 때, 표준편차를 시각적으로 같이 표시해주는 방법을 도입하면 매우 직관적이고 유용한 시각화가 될 수 있다.
# 샘플 데이터 생성 (원시 데이터에 대한 평균, 표준편차를 구해 둔 결과)
categories = ['Category A', 'Category B']
means = [5, 7] # 각 범주의 평균
std_dev = [0.5, 0.8] # 각 범주의 표준 편차
# 그래프 생성
plt.bar(categories, means, yerr=std_dev, capsize=5, color='skyblue', alpha=0.7)
# 그래프에 라벨과 제목 추가
plt.xlabel('Categories')
plt.ylabel('Mean Value')
plt.title('오차 막대 그래프 예제')
# 오차 막대의 색상 및 스타일 설정
plt.errorbar(categories, means, yerr=std_dev, fmt='o', color='black', markersize=5, capsize=5)
# 그래프 표시
plt.show()
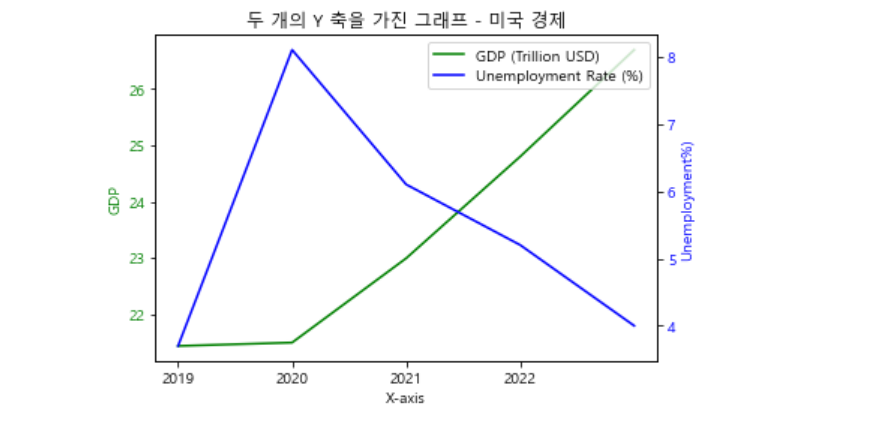
[5] 병렬 좌표계 사용: plt.twinx() 또는 plt.twiny()를 사용하여 두 개의 병렬 좌표계를 사용하여 그래프를 그릴 수 있습니다.
이 예제에서는 두 개의 데이터 세트 y1와 y2를 각각 첫 번째 Y 축과 두 번째 Y 축에 그래프로 표시합니다.
엑셀에서 이중축 챠트를 그리는 것과 같은 기능입니다.
# 샘플 데이터 -- 미국의 최근 5년 GDP와 실업률
data = [
{"Year": 2019, "GDP (Trillion USD)": 21.43, "Unemployment Rate (%)": 3.7},
{"Year": 2020, "GDP (Trillion USD)": 21.49, "Unemployment Rate (%)": 8.1},
{"Year": 2021, "GDP (Trillion USD)": 22.99, "Unemployment Rate (%)": 6.1},
{"Year": 2022, "GDP (Trillion USD)": 24.80, "Unemployment Rate (%)": 5.2},
{"Year": 2023, "GDP (Trillion USD)": 26.70, "Unemployment Rate (%)": 4.0}
]
data = pd.DataFrame(data)
x = data["Year"].astype(int)
y1 = data["GDP (Trillion USD)"]
y2 = data["Unemployment Rate (%)"]
# 그래프 생성
fig, ax1 = plt.subplots()
# 두 번째 Y 축 추가
ax2 = ax1.twinx()
# 첫 번째 Y 축에 그래프 그리기
ax1.plot(x, y1, 'g-', label='GDP (Trillion USD)')
ax1.set_ylabel('GDP', color='green')
ax1.tick_params(axis='y', labelcolor='green')
# 두 번째 Y 축에 다른 그래프 그리기
ax2.plot(x, y2, 'b-', label='Unemployment Rate (%)')
ax2.set_ylabel('Unemployment%)', color='blue')
ax2.tick_params(axis='y', labelcolor='blue')
# X 축 라벨 추가
ax1.set_xlabel('X-axis') # 'Year' 라고 바꿔주는 것이 적합할
# 범례 추가
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax2.legend(lines1 + lines2, labels1 + labels2, loc='upper right')
# x 축의 눈금을 정수로 설정
plt.xticks(np.arange(2019, 2023, 1)) # 연도단위인 기간 내에서 정수로 눈금 설정
# 그래프 표시
plt.title('두 개의 Y 축을 가진 그래프 - 미국 경제')
plt.show()
'Python데이터분석' 카테고리의 다른 글
| Sales EDA - Fashion Brand (0) | 2024.12.04 |
|---|---|
| [ FCPEDA ] 패션 고객-상품 탐색적 데이터 분석 - PYTHON (40) | 2024.10.11 |
| 파이썬 데이터 분석: 쉽지만 잘들 모르는 유용한 팁 10 (0) | 2023.12.25 |
| [온라인 서점 고객세분화] ChatGPT가 지원하는 디지털 마케터의 시장/고객 데이터 분석 (2) | 2023.12.04 |
| styleMarket 데이터분석 : 보헤미안브리즈 고객세분화 분석 PYTHON (1) | 2023.11.29 |