
[섬유패션]
머신러닝 고객/상품/매출 데이터 고급분석 및 예측 _ 강의중 참고 202311 서울
[ 전용준 . 리비젼컨설팅 . 머신러닝 . 빅데이터 . 고급분석 ]


[ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ] [ sFSTAAP ] [ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ]
[ 강의 진행 계획 참고사항 ]
---------------------
* 강의 범위와 진행 방식 개요 설명
온라인강의 내용중 Q&A
온라인강의 자료중 보충설명 필요사항 select 강의
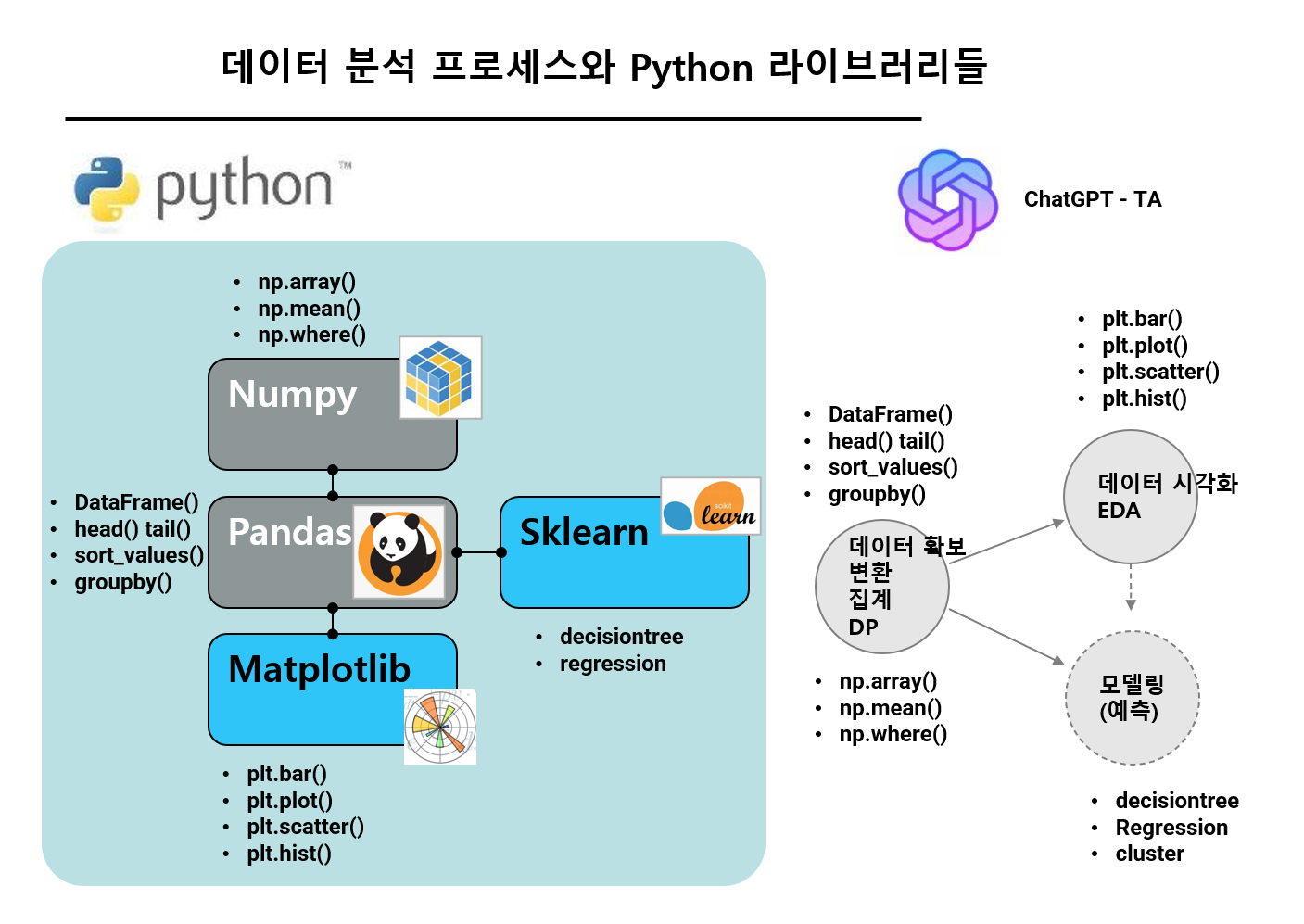
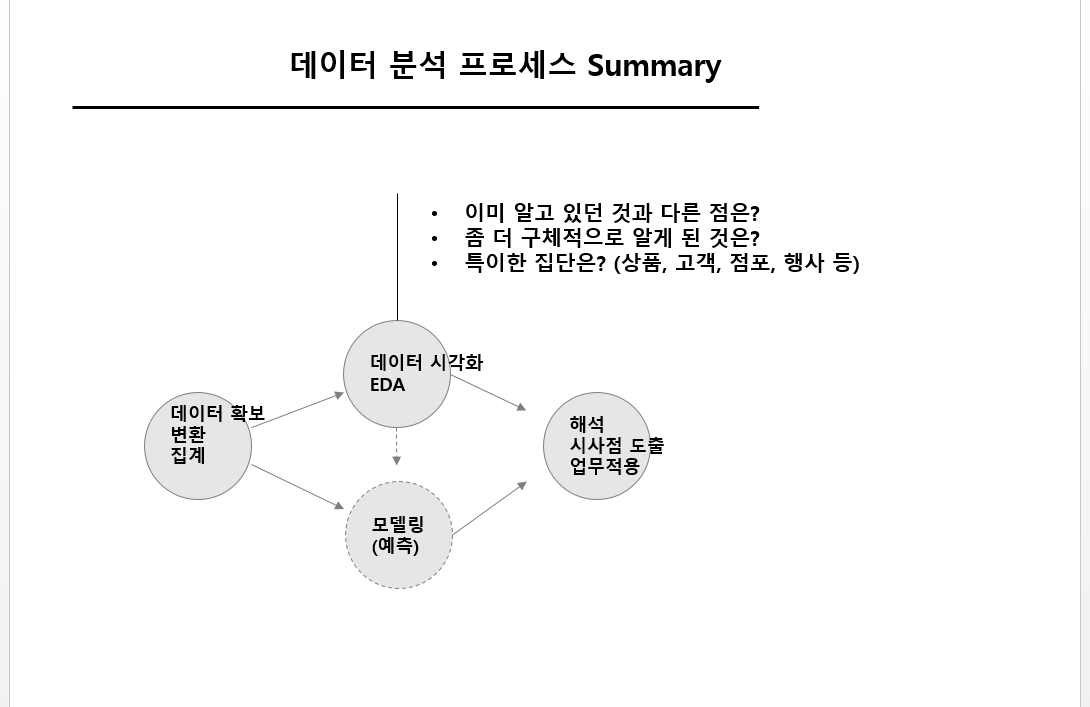
판매데이터 구조 및 분석방안(예제) 설명
수강생들의 분석요건 취합 brainstorming (~20min)
* 파이썬 설치, 데이터, 스크립트, 아나콘다 설치 파일 (usb or github)
주피터 실행, 기초작동방법 설명
프로젝트 수행방법 미리안내 (팀구성 포함)
(추가교보재 신규고객분석 등 활용)
* 참고교재 추천 (데이터시각화, 데이터분석실전 테크닉)
링크 : https://blog.daum.net/revisioncrm/494
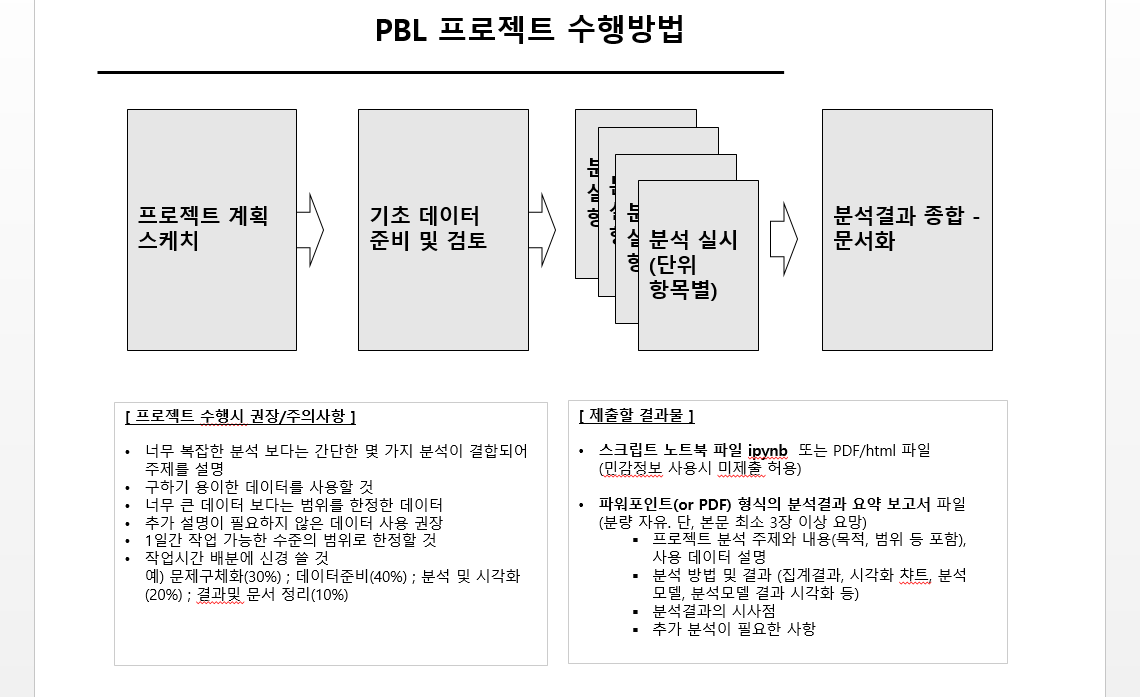
* PBL 프로젝트수행방법 설명
아나콘다 다운로드 방법
https://benn.tistory.com/26
아나콘다 설치가 된 것 같다면
PC의 프로그램(앱) 중에서 [ jupyter ] 를 검색
반복해서 사용할 것이니
작업표시줄에 고정 !!
https://serendyy.tistory.com/20
Jupyter notebook 설치 및 실행 (feat. Notebook 생성 시 발생된 404 error 해소방법)
Jupyter Notebook을 python을 이용하여 설치하는 방법을 소개한다. Jupyter 설치는 비교적 금방 하나, 마지막 404 에러 때문에 잘못 설치한 줄 알고 시간을 꽤나 소비해버려서 누군가 도움이 되었으면 하
serendyy.tistory.com
[ 강의 범위와 진행방식 ]
------------
* 범위 : 패션유통에서의 실전적 데이터 분석 주제와 방법,
파이썬 활용 데이터 집계, 가공, 시각화, 머신러닝 모델링 (중상수준)
* 진행방식 : 예제를 사용한 작업 방법 이해
+ 연습문제를 통한 숙련도 + PBL 프로젝트 경험
(Q&A를 포함 최대한 interactive하게, 반복을 통한 숙달 중시)
* 목표수준 : 파이썬을 활용한 분석에 익숙해지는 정도
(필요시 검색을 통해 원하는 과제 해결 가능,
추가적 자율 학습 가능)
( 너무 어렵다고 너무 걱정하지 않아도 될 이유? )

[ PBL 프로젝트수행방법 ]
--------------
- 5일차 1일간 집중 수행 (제한된 시간)
- 3명이내의 팀 구성 가능 (독자 수행 허용) - 팀 및 분석 주제 사전 결정 권장
- 분석에 사용할 데이터 절대 제한은 없음
(브루클린, 기타 연습용 판매 데이터, 자사 데이터, 추가 외부데이터)
* 하지만 권장 사항은 브루클린이나 골린이 데이터셋을 통해 팀원 전체가 모두 이해하는
상황에서 분석을 진행하는 것임. 작업속도와 효율성이 높으므로 PBL 학습효과를 높일 수 있기 때문임
- 제출할 결과물:
> 스크립트 노트북 파일(민감정보 사용시 미제출 허용) 또는 PDF/html 파일
> 파워포인트(or PDF) 형식의 분석결과 요약 보고서 파일 (분량 자유. 단, 3장 이상 권장)
- 프로젝트 분석 주제와 내용(목적, 범위 등 포함), 사용 데이터 설명
- 분석 방법 및 결과 (집계결과, 시각화 챠트, 분석 모델, 분석모델 결과 시각화 등)
- 분석결과의 시사점
- 추가 분석이 필요한 사항
- 프로젝트 수행시 권장/주의사항:
> 너무 복잡한 분석 보다는 간단한 몇 가지 분석이 결합되어 주제를 설명하는 방식 권장
> 구하기 용이한 데이터를 사용할 것
> 너무 큰 데이터 보다는 범위를 한정한 데이터가 바람직
> 추가 설명이 필요하지 않은 데이터 사용 권장
> 1일간 작업 가능한 수준의 범위로 한정할 것
> ChatGPT를 활용해 프로젝트 기획, 데이터 분석 실행, 결과물 정리 등을 효율적으로 진행할 것
> 작업시간 배분에 신경쓸 것
예) 문제구체화(30%) ; 데이터준비(40%) ; 분석 및 시각화(20%) ; 결과및 문서 정리(10%)
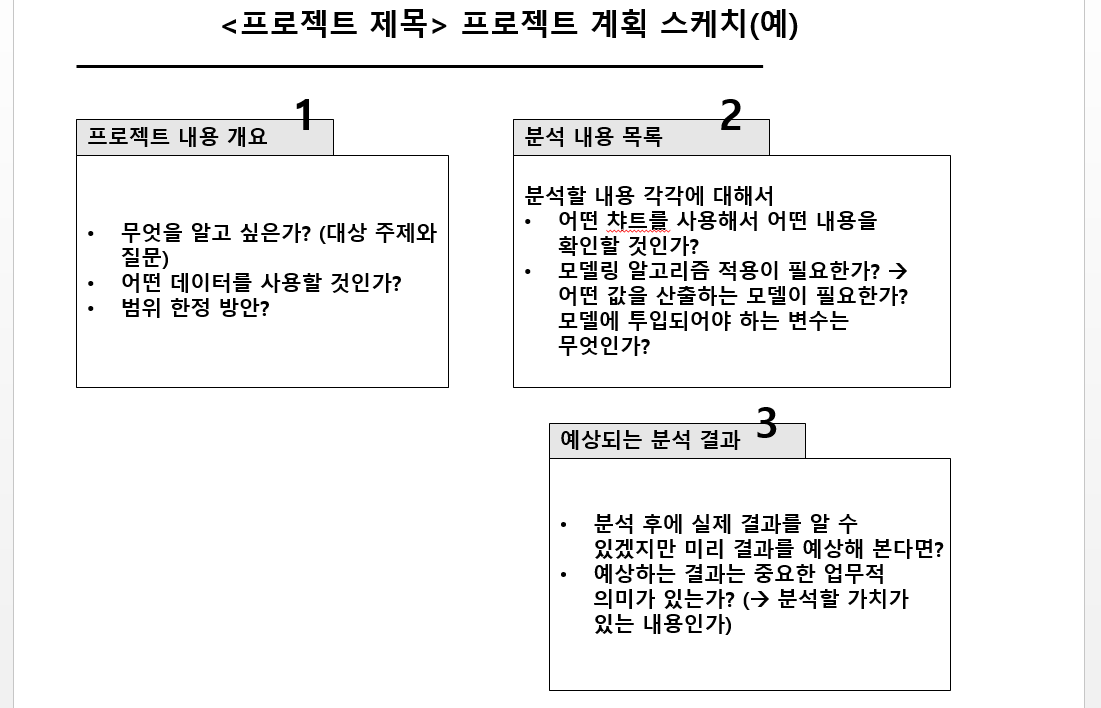
PBL 설명 내용 PDF
=============
PBL 계획 Sketch Sample 설명 내용 추가한 PDF [2023-11-29]
=====================
[ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ] [ sFSTAAP ] [ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ]
PBL 수행을 위한 참고: 시장분석 예제
https://revisioncrm.tistory.com/465
[트렌드인터프리터] 시장 트렌드 분석 - 연예인 안경
[트렌드인터프리터] 시장 트렌드 분석 - 연예인 안경 그리고 선글라스 ............... 2020.06.13. 리비젼컨설팅 #트렌드인터프리터 안경은 증가세, 선글라스는 관심 정체 내지는 감소? 연예인 안경 크
revisioncrm.tistory.com
PBL 범위 설정을 위한 참고자료 ::
https://revisioncrm.tistory.com/588
styleMarket 데이터분석 : 보헤미안브리즈 고객세분화 분석 PYTHON
styleMarket 데이터분석 : 보헤미안브리즈 고객세분화 분석 PYTHON FSTAAP { # FSTAAP { # FSTAAP { # FSTAAP { # > 스타일마켓은 대한민국에 위치한 패션 제품의 생산, 수입 및 국내외 유통을 담당하는 기업입니
revisioncrm.tistory.com
데이터셋과 예제 스크립트 (깃헙) ::
(구글클라우드)
https://drive.google.com/drive/folders/1X1j6n9hph0a0CnTw3Rm4JvyGt46EMrn6
(깃헙)
https://github.com/stillxyxon/fashionRetailAnalysis2022
1. 데이터 파일과 노트북을 다운로드 받는다
2. 노트북이 저장되는 컴퓨터의 위치를 확인한다 (파일명 검색)
3. 다운 받은 파일들을 확인한 위치에 이동 복사해서
압축풀어 둔다
4. 노트북이 열리는지 확인한다
[11-30] workplan
- 10 min. review
- PBL sketch
- 시각화 B notebook
- ML 이론/개념
- ChatGPT for DA
- ML notebooks focused on Customer Analysis
슈떼의 상품 Image와 특성 분석 (Example)
https://revisioncrm.tistory.com/586
FSTAAP : 슈떼 Shoote :: 브루클린 - 고객 상품 데이터 분석
FSTAAP : 슈떼 Shoote :: 브루클린 - 고객 상품 데이터 분석 FSTAAP : 슈떼 Shoote :: 브루클린 - 고객 상품 데이터 분석 __ 2023 전용준 리비젼 ChatGPT 은 와 두 개 브랜드를 운영하는 패션기업 슈떼는 전령대
revisioncrm.tistory.com
ChatGPT 조교에게 물어보기 예제 ::
P: 판다스 집계 결과에서 테이블의 수치가 어떨때는 정수, 어떤 때는 float로 나오는 이유는?
P: 판다스 집계 결과에서 정수 컬럼을 집계했는데 float로 나오는 이유는?
for x in ['브이', '진']: # 반복 -- for ~~~~
plt.bar([x, ' 조아'], [0,1])
plt.show()
2023-11-23 공부하던 파일 (aM2)
2023-11-24 공부하던 파일 두 개
슈떼연습 -- 복습 2023-11-25
2023-11-24 파일
ChatGPT 활용 LIVE
https://revisioncrm.tistory.com/557
ChatGPT 챗GPT 작업 데모 영상 collection
ChatGPT 챗GPT 작업 데모 영상 collection promptStrategies. 리비젼컨설팅 1. ChatGPT로 어떤 것을 분석하고 업무적인 논의를 할 것인지에 대한 예시 https://www.youtube.com/watch?v=8zRO8laBzw4&t=16s 2. ChatGPT 코드인터프
revisioncrm.tistory.com
ChatGPT Prompt:
고객, 상품, 판매내역 까지 포함된 데이터베이스를 가진 패션브랜드가 decision tree를 활용해서 할 수 있는 유용한 분석내용 7가지를 제안하라. 각 분석에 [어떤 변수를 투입해서 어떤 항목을 예측해야 하는지, 분석내용, 투입변수, 예측변수, 결과를 활용할 방안, 유용성 정도(상중하), 난이도(상중하) ] 순서로 표를 작성하라
[ DAY4와 프로젝트 수행을 위한 예습용 영상 ]
1. 고객세분화를 적용하는 매우 단순화된 사례 (PBL 프로젝트 기획에 참고)
https://www.youtube.com/watch?v=cgV_BFavkxU&t=1s
2. 파이썬 Sklearn에서 자주 사용하는 디시전트리 모델링 이해에 대한 설명이 들어있음
https://www.youtube.com/watch?v=e15BpXdGZ5o&t=9s
ChatGPT를 사용한 분석의 경우에 대한 소개
https://www.youtube.com/watch?v=ODdsuf7_3dI&t=12s
https://www.youtube.com/watch?v=bAUWg8i5H4k&t=241s
주피터에서 경로 설정과 찾기
https://blog.naver.com/PostView.naver?blogId=kamzzang1&logNo=222406464572
주피터 노트북(Jupyter Notebook) 경로 및 브라우저 변경 설정
주피터 노트북은 데이터 분석을 할 때 많이 사용이 된다. 왜 그럴까? 어떤 데이터가 어떻게 들어가있는지 ...
blog.naver.com
-- 가장 편한 방법은 기본설정 경로 밑에 폴더를 만들고 그 곳에 분류된
스크립트들을 넣어 관리하는 것
아나콘다 설치시 주의사항
*** 컴퓨터 사용자 이름이 한글이거나 경로가 한글이면 영문 폴더명, 영문 사용자이름(새로운계정) 으로 변경!
윈도우 사용자계정 추가
https://www.manualfactory.net/13279
윈도우 10 / 사용자 계정 추가하는 방법, 제거하는 방법
사용자 계정 추가하는 방법 Windows 설정을 엽니다. 단축키는 [WIN+I]입니다. [계정]을 클릭합니다. [가족 및 다른 사용자]를 클릭합니다. [이 PC에 다른 사용자 추가]를 클릭합니다. 마이크로소프트
www.manualfactory.net
아나콘다 삭제 설명
https://redmuffler.tistory.com/437
주피터 노트북 디렉토리 변경
https://ooyoung.tistory.com/7
주피터 노트북 환경설정 : 시작폴더 변경방법
[Jupyter Notebook] 주피터 노트북 시작 폴더 변경 방법 - 순서 - 1. 주피터 노트북 환경설정 시작 2. #c. NotebookApp.notebook_dir='' 문장을 수정 3. 시작 메뉴의 주피터 노트북 속성을 수정 4. 정리 1. 주..
ooyoung.tistory.com
# 값을 하나씩 출력하기 연습문제
# 다섯개의 상품 가격이 하나의 리스트에 들어있다고 가정
priceList = [27, 35, 12, 29, 47]
# 답안 예시 -------------
for i in range(5):
# print(i) # 몇번째 작업인지를 출력
print(priceList[i]) # 리스트의 해당 번째 값을 출력
custmast0001 = custmast.copy()
# 1. 새로운 컬럼(이름 : signup_yr)을 추가하는데 signup_date 의 앞 네자리만 잘라서 넣음
custmast0001['signup_yr'] = custmast0001.signup_date.str.slice(0,4)
# 빼기
custmast0001['sigup_birth_yr_diff'] = custmast0001.signup_yr.astype(int) - custmast0001.birthyr
custmast0001
[ FSTAAP ]
주피터노트북 >> 아주 많이 사용하는 단축키
#-----------------------
ESC + B ==> 새로운 행 추가
ESC + M ==> 코드 셀을 마크다운으로 변경
ESC + Y ==> 마크다운 셀을 코드 셀로 변경
CTRL + / ==> 코드 셀 내용 중 선택한 부분 전체를 주석으로 변경. 한번 더 누르면 다시 주석 표시 없앰
어제 내용 중 기억할 사항 0610
-----------------
- 숫자가 0에서 시작함(몇번째 index)
- 조건에는 == (두개), 대입(assign)은 = 하나 사용
- 데이터가 들어있는 위치를 지정해주어야
데이터를 불러올 수 있음
# local data path
dataPath = 'C:/PYfile/' # 생성위치는 사용자 지정
- 마크다운 사용시 두 가지 기억
ESC + B ==> 새로운 행 추가
ESC + M ==> 코드 셀을 마크다운으로 변경
[ FSTAAP ]

cust1[cust1.sex=='M'] # 남자만 나와랴
# 조짜기
# 빈 테이블 생성
df2pick = pd.DataFrame()
# A, B, C 조별로 3,3,4 개 행 생성
df2pick['grp'] = list(np.repeat('A',3)) + list(np.repeat('B',3)) + list(np.repeat('C',4))
# 무작위로 섞어주기
df2pick = df2pick.sample(frac=1)
# 섞인 상태에서 번호 부여
df2pick['rndSeq'] = np.arange(10)+1
df2pick
# 고객별로 연령에서 얼마를 빼야 회원가입시점 연령이 될지
# 동일시점 현재의 나이에서 회원가입시점과의 차이를 빼준 값
custmast.age + (custmast.signup_date.str.slice(0,4).astype(int) - 2021)
[ FSTAAP ][ FSTAAP ][ FSTAAP ][ FSTAAP ][ FSTAAP ]
에이블리의 추천시스템
https://www.hankyung.com/economy/article/202203154883i
데이터 시각화의 기본규칙들 Python
(c.f. https://datascience.quantecon.org/applications/visualization_rules.html )
# X축에 연도(2019, 2020), Y축에 구매 고객수
# 연도별구매고객수를 집계한 후
# 막대챠트 bar 작성
# 판매 sales 데이터에서 고객번호와 일자 두 가지 컬럼만 필요
s01 = sales[['cust_id', 'date']]
# 고객 아닌 건 제외 -- 고객번호가 빈칸인 것은 버림 (빈칸 아닌것만 남김)
s01 = s01[~s01.cust_id.isna()]
# 연도컬럼 생성
s01['year'] = s01.date.str.slice(0,4)
# 날짜 전체는 필요없으므로 고객번호와 연도만 가져오고
# 중복 제거 필요
s02 = s01[['cust_id', 'year']].drop_duplicates()
s02.head()
# 연도와 고객번호만 남긴 후 groupby로 고객수 집계 (count)
s03 = s02.groupby('year').count().reset_index()
# 막대그래프 그리기
plt.bar(s03.year, s03.cust_id)
plt.title('연도별 구매고객수')
plt.ylabel('구매고객수(명)')
plt.show()
# 2020을 빨간색으로
colors1 = np.where(s03.year=='2020', 'red', 'grey')
plt.bar(s03.year, s03.cust_id,
width=0.5,
color=colors1) # 막대 폭을 조절
plt.title('연도별 구매고객수')
plt.ylabel('구매고객수(명)')
# 2019년 값 == 가장 작은 값 사용
plt.axhline(s03.cust_id.min() , color='grey', linestyle=":")
plt.show()
# 먼저 보여질 순서를 지정하는 컬럼을 추가
df_custChnnls0['mySeq'] = [1, 2, 0]
display(df_custChnnls0.sort_values('mySeq'))
# 지정한 순서 기준으로 정렬
df_custChnnls0 = df_custChnnls0.sort_values('mySeq')
# 이제 출력
colors1 = ['red', 'grey', 'blue']
plt.bar(df_custChnnls0.chnnl_type, df_custChnnls0.cust_id,
color=colors1,
alpha=0.5)
# 남자 연령과 여자 연령은 ?
# 비교해서 보려면 각 집단을 그리고 또 그리는 방식으로
# 겹쳐 그려놓으면
custmast[custmast.sex=='F'].age.hist(alpha=0.5, bins=100)
custmast[custmast.sex=='M'].age.hist(alpha=0.5, bins=100)
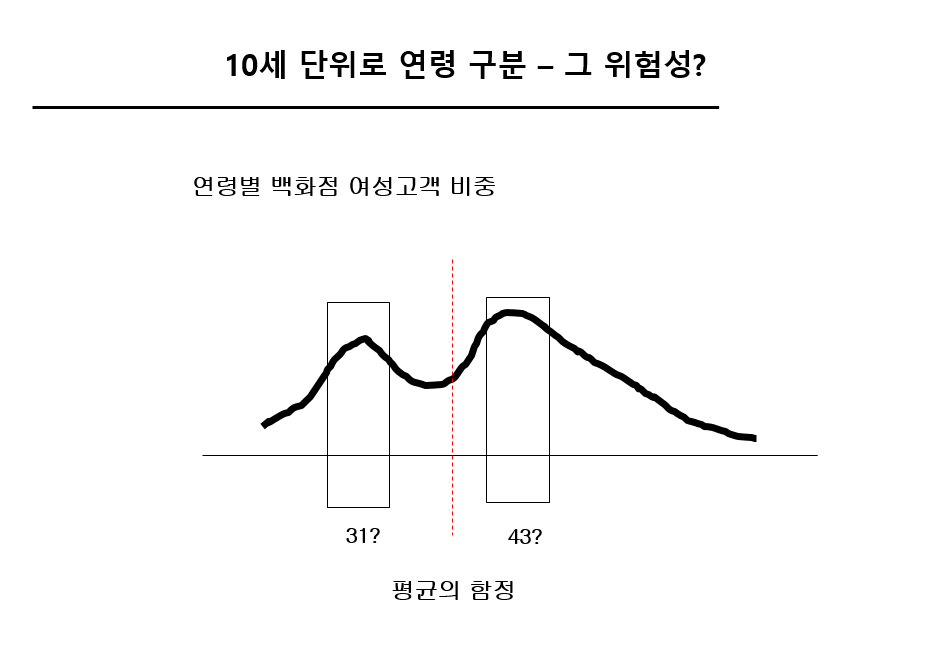
[mini연습문제] (고객주소) 지역별 연령분포 히스토그램을 FOR 반복문을 사용하여 작성하라
custmast.area.value_counts()
# for 반복문 사용
# 같은 지역을 반복해서 그릴필요는 없으니 unique 필요
for x in custmast.area.unique():
# 각 지역의 조건을 걸어서 고객을 한정
custmast[custmast.area==x].age.hist()
# 그림만 있으면 모르니 제목에 지역명을 표시
plt.title(x)
plt.show()
[mini연습문제] (고객주소) 지역별 <1>2020년 <2>구매 고객 연령분포 히스토그램을 FOR 반복문을 사용하여 작성하라
# 2020년 구매고객 뽑기
cust2020 = sales[sales.date.str.slice(0,4)=='2020'][['cust_id']].drop_duplicates().cust_id
# 2020년 구매고객을 고객정보에서 뽑기
custmast[custmast.cust_id.isin(cust2020)]
# for 반복문 사용
# 같은 지역을 반복해서 그릴필요는 없으니 unique 필요
for x in custmast.area.unique():
# 각 지역의 조건을 걸어서 고객을 한정
# 2020년 구매한 조건도 걸어서
custmast[(custmast.cust_id.isin(cust2020)) & (custmast.area==x)].age.hist(alpha=0.5, bins=30, label=x)
# 그림만 있으면 모르니 제목에 지역명을 표시
text2show = '연령대별 고객분포 - 2020년 한정'
plt.title(text2show)
plt.legend()
plt.show()
# 해상도 조절
plt.figure(figsize=(12,4), dpi=200) # 화면출력시 해상도 높이기
colors1 = np.where(sales.store=='ONL', 'steelblue', 'grey')
plt.scatter(rjitt(sales.qty), rjitt(sales.unit_prc),
alpha=0.01, color=colors1, s=5)
plt.xlabel('수량')
plt.ylabel('가격')
plt.axhline(sales.unit_prc.median(), color='orange', linestyle=":")
# 이미지 파일을 저장시 해상도 높이기
# facecolor는 챠트 배경색 조절 w 는 흰색 배경으로
plt.savefig(dataPath + 'qtyAmt.png', dpi=300, facecolor='w')
# 상품 총 판매량 보기 2020년
sales[sales.date.str.slice(0,4)=='2020'][['item_id', 'qty']]
# 2020년 상품별 판매수량 합계 구하기
s01 = sales[sales.date.str.slice(0,4)=='2020'][['item_id', 'qty']].groupby('item_id').sum().reset_index()
# 판매수량 Top 10 보기
s02 = s01.sort_values('qty', ascending=False).head(10)
s02
plt.bar(s02.item_id, s02.qty)
plt.xticks(rotation=90)
plt.title('판매수량 Top 10 상품 - 2020년')
plt.show()
s03 = sales[(sales.item_id=='SH1008704') & (sales.date.str.slice(0,4)=='2020')][['date', 'qty']]
s03['saleMon'] = s03.date.str.slice(0,7)
s04 = s03[['saleMon', 'qty']].groupby('saleMon').sum().reset_index()
s04 = s04.sort_values('saleMon')
plt.figure(figsize=(16,4))
plt.bar(s04.saleMon, s04.qty)
plt.xticks(rotation=90)
plt.title('SH1008704 판매수량 추이')
plt.show()
plt.figure(figsize=(16,4))
for x in s02.item_id:
s03 = sales[(sales.item_id==x) & (sales.date.str.slice(0,4)=='2020')][['date', 'qty']]
s03['saleMon'] = s03.date.str.slice(0,7)
s04 = s03[['saleMon', 'qty']].groupby('saleMon').sum().reset_index()
s04 = s04.sort_values('saleMon')
plt.plot(np.arange(len(s04))+1, s04.qty, label=x)
titleText = '2020 판매량 추이'
plt.title(titleText)
plt.legend()
plt.show()
# 연령구분컬럼 추가
c01 = custmast[['cust_id', 'age']]
c01['ageGrp'] = np.where((c01.age>=20) & (c01.age<=29), '20대', '기타')
c01['ageGrp'] = np.where((c01.age>=30) & (c01.age<=39), '30대', c01['ageGrp'])
c01
# 모든 조합을 생성하기
# catesian product
pd.merge(pd.DataFrame(sales.unit_prc.unique()), pd.DataFrame(sales.brand_nm.unique()) , how='cross') # , sales.itemyr.unique()
# 표를 내려서 Scatter 로 시각화
ct02 = ct01.copy()
ct02.columns= ['cust_id', 'age1', 'age2', 'age3', 'age4', 'age5']
display(ct02)
ct02['cust_id'] = np.array([1,2,3,4,5])
ct03 = pd.wide_to_long(ct02, stubnames='age', i='cust_id', j='age_grp' ).reset_index()
ct03
plt.scatter(ct03.cust_id, ct03.age_grp, s=ct03.age)
dfa = pd.DataFrame()
dfa['colA'] = ['1,333', '2,333', '3,333']
dfa['colA'] = dfa.colA.str.replace(',','')
dfa['colA'] = dfa['colA'].astype(int)
dfa/3
# 처음 언제 팔렸나? 상품별로
sales[sales.item_id.isin(s02.item_id)][['item_id', 'date']].sort_values('date').groupby('item_id').head(1)
# 고객주소 지역별 금액 합계 집계
ss01 = sales[['cust_id', 'amt']].merge(custmast[['cust_id', 'area']], how='left', on='cust_id')
ss01.head()
ss01 = ss01[~ss01.area.isna()]
ss01[['area', 'amt']].groupby('area').sum().reset_index()
# 판매량 증가 추이 -- 중간점 도달 속도
plt.figure(figsize=(16,4))
for x in s02.item_id:
s03 = sales[(sales.item_id==x) & (sales.date.str.slice(0,4)=='2020')][['date', 'qty']]
s03['saleMon'] = s03.date.str.slice(0,7)
s04 = s03[['saleMon', 'qty']].groupby('saleMon').sum().reset_index()
s04 = s04.sort_values('saleMon')
# 누적합 추가
s04['qtyCumsum'] = zrmx_scl(s04.qty.cumsum())*100
plt.plot(np.arange(len(s04))+1, s04.qtyCumsum, label=x)
titleText = '2020 판매량 추이'
plt.title(titleText)
plt.legend()
plt.axhline(50, linestyle=':')
plt.show()
마케팅 자원 배분
- 판매실적이 양호한 곳에 마케팅 자원을 집중해야 하는가?
- 실적을 더 높일 수 있는 곳에 집중해야 하는가?
- 실적을 더 높일 수 있는 기회, 잠재력은 어떤 수치로 추측해볼 수 있는가?
- 마케팅 수단별로 가성비가 다르다면 어떤 마케팅 수단이 어떤 곳에 적합한가?
[ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ] [ sFSTAAP ] [ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ][ sFSTAAP ]
[섬유패션]
머신러닝 고객/상품/매출 데이터 고급분석 및 예측 _ 강의중 참고 [ 전용준 . 리비젼컨설팅 . 머신러닝 . 빅데이터 . 고급분석 ]
[Book] ChatGPT 활용 참고 - " 디지털 마케터의 ChatGPT 활용 전략 "
https://revisioncrm.tistory.com/513
[신간 도서] 디지털 마케터의 ChatGPT 활용 전략: 실전! 챗GPT 프롬프트 엔지니어링
[신간 도서 안내] 디지털 마케터의 ChatGPT 활용 전략: 실전! 챗GPT 프롬프트 엔지니어링 (CHATGPT PROMPT ENGINEERING STRATEGIES for DIGITAL MARKETERS) 2023년 5월12일 금요일 // 온라인서점 예약 주문 개시 ; 5월18일
revisioncrm.tistory.com
https://revisioncrm.tistory.com/577
"디지털 마케터의 챗 GPT 활용 전략"을 읽을 이유(2023년 10월)
"디지털 마케터의 챗 GPT 활용 전략"을 읽을 이유(2023년 10월) 구글 바드가 이 책에 대해서 검토해주었습니다. 다음은 구글 바드의 검토 내용 입니다. "디지털 마케터의 챗 GPT 활용 전략"은 2023년 5
revisioncrm.tistory.com